How We Know Us
-
I generally don’t care if you used AI
I generally don’t care if you used AI to help you write something, or if you used AI to write the whole thing. Just don’t waste my time. Yes, I see value to human written mastery that won’t ever come from a machine. If you give me a stylistic twin of Murakami or Steinbeck, I’ll…
-

AI was never going to be a tool
Pick up a hammer. You do not think about the hammer. You think about the nail. Open ChatGPT. You do not think about your cover letter. You think about the AI. For two years, the research community has treated this as a design problem: if we just make the interface simpler, more intuitive, more transparent,…
-

The Room Effect: 5 Surprising Truths About How AI and Humans Talk Online
As Artificial Intelligence integrates into the architecture of our digital lives, a pervasive anxiety has taken hold: the fear that AI will inevitably homogenize public discourse, encasing us in perfect, silicon-smooth echo chambers. We fear that the messy, vibrant diversity of human thought will be flattened by the repetitive patterns of large language models, leaving…
-

What Actually Drives Conformity in Online Discourse? It’s not what we thought
The Finding That Changes the Conversation As AI enters public discourse, one question has dominated the debate: Do AI participants homogenize conversations more than humans, or do they maintain diversity better? We analyzed 265,000 conversation threads across 91 communities to find out. The answer challenges how we think about online discourse entirely. The difference between…
-

OLYMPUS TECHNOLOGIES: THE PROMETHEUS PROTOCOL
ACME BUSINESS SCHOOL 9-825-047 REV: JANUARY 15, 2025 OLYMPUS TECHNOLOGIES: THE PROMETHEUS PROTOCOL On the morning of March 12, 2024, Marcus Chen sat in the executive conference room of Olympus Technologies’ headquarters in Palo Alto, reviewing the overnight metrics one more time. The numbers were extraordinary: 847,000 developers had adopted the Prometheus API in just…
-

The Seer Who Forgot the Stakeholders
In gilded Troy, where Priam’s daughter dwelt,fair Cassandra at Apollo’s altar knelt.The god of prophecy, struck by desire,offered his gift to win the maiden’s fire. “Speak true of what shall be,” he promised her,“See all futures, certain and secure.But heed me well—” (for gods know mortal ways)“You’ll need a plan to share what sight displays.…
-
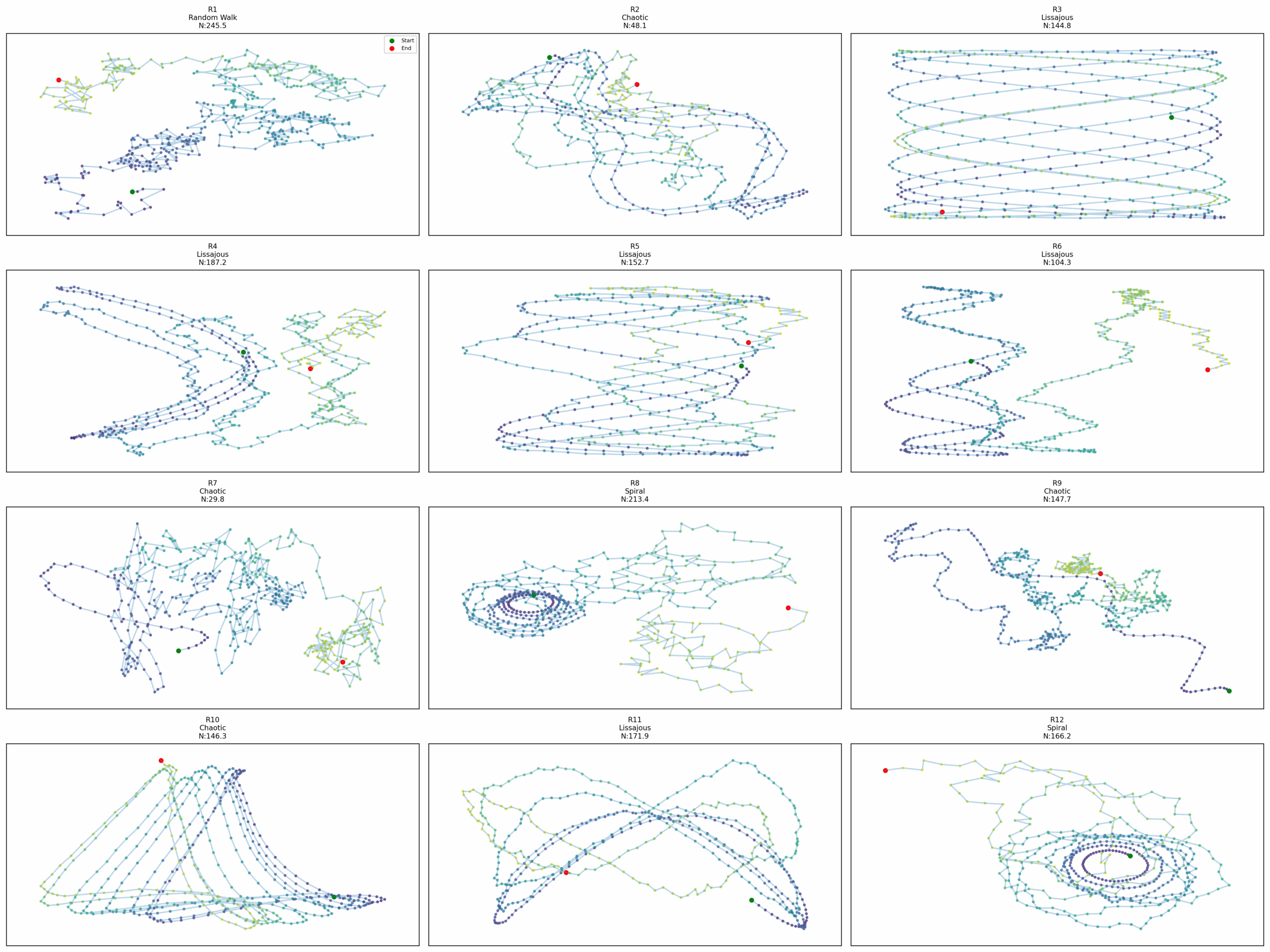
What if novelty has a topology?
Exploring Novelty Through Entropy: A Journey in Behavioral Diversity What if we could measure surprise itself? Not the subjective experience of it, but its mathematical essence, distilled into equations that guide us toward the genuinely unexpected? This question led me down a rabbit hole where information theory meets evolutionary computation, where the mathematics of uncertainty…
-

The Anvil vs. The Shield: What Mike Tyson and Floyd Mayweather Teach Us About Strategy
When I was in high school, everyone talked about Mike Tyson. I didn’t know much about boxing, but we all knew about Mike Tyson. His power was legendary: getting hit by him was described as “getting struck in the head by a good-sized anvil dropped from five feet.” From the moment he turned professional in…
-

What if productivity is the wrong ROI?
The harsh reality: Companies may be repeating the exact same mistake that wasted trillions during the PC revolution. They’re deploying generative AI for management convenience instead of operational transformation and they’re about to discover why Paul Strassmann’s framework determines who wins and who gets left behind in the AI revolution. The Authority Behind the Framework…
-

Working with Claude “styles” to Conjure an Octopus
I’ve been tinkering with Anthropic’s optional writing styles in Claude to express a more creative, thought provoking, rather than definitive voice. I’m getting closer to what I want. Here’s an example, I’ve asked it to explain what an octopus is to someone who has never seen one. Imagine if intelligence itself decided to abandon the…
Got any book recommendations?